通俗的理解,事务是一组原子操作单元。我们希望一些列的操作能够全部正确执行,如果这一组操作中的任意一个步骤发生错误,那么就需要回滚之前已经完成的操作。也就是同一个事务中的所有操作,要么全都正确执行,要么全都不要执行。
传统的单机应用系统一般使用一个关系型数据库,利用数据库事务来保证数据的一致性,下面先了解一下本地数据库事务的一些特性。
一、本地数据库事务
事务从数据库角度说,就是一组 SQL 指令,要么全部执行成功,若因为某个原因其中一条指令执行有错误,则撤销先前执行过的所有指令。
关系型数据库(例如:MySQL、SQL Server、Oracle 等)事务都有以下几个特性:原子性(Atomicity)、一致性(Consistency)、隔离性或独立性(Isolation)和持久性(Durabilily),简称就是 ACID。
- 原子性:表示事务执行过程中的任何失败都将导致事务所做的任何修改失效。
- 一致性:表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态。
- 隔离性:表示在事务执行过程中对数据的修改,在事务提交之前对其他事务不可见。
- 持久性:表示已提交的数据在事务执行失败时,数据的状态都应该正确。
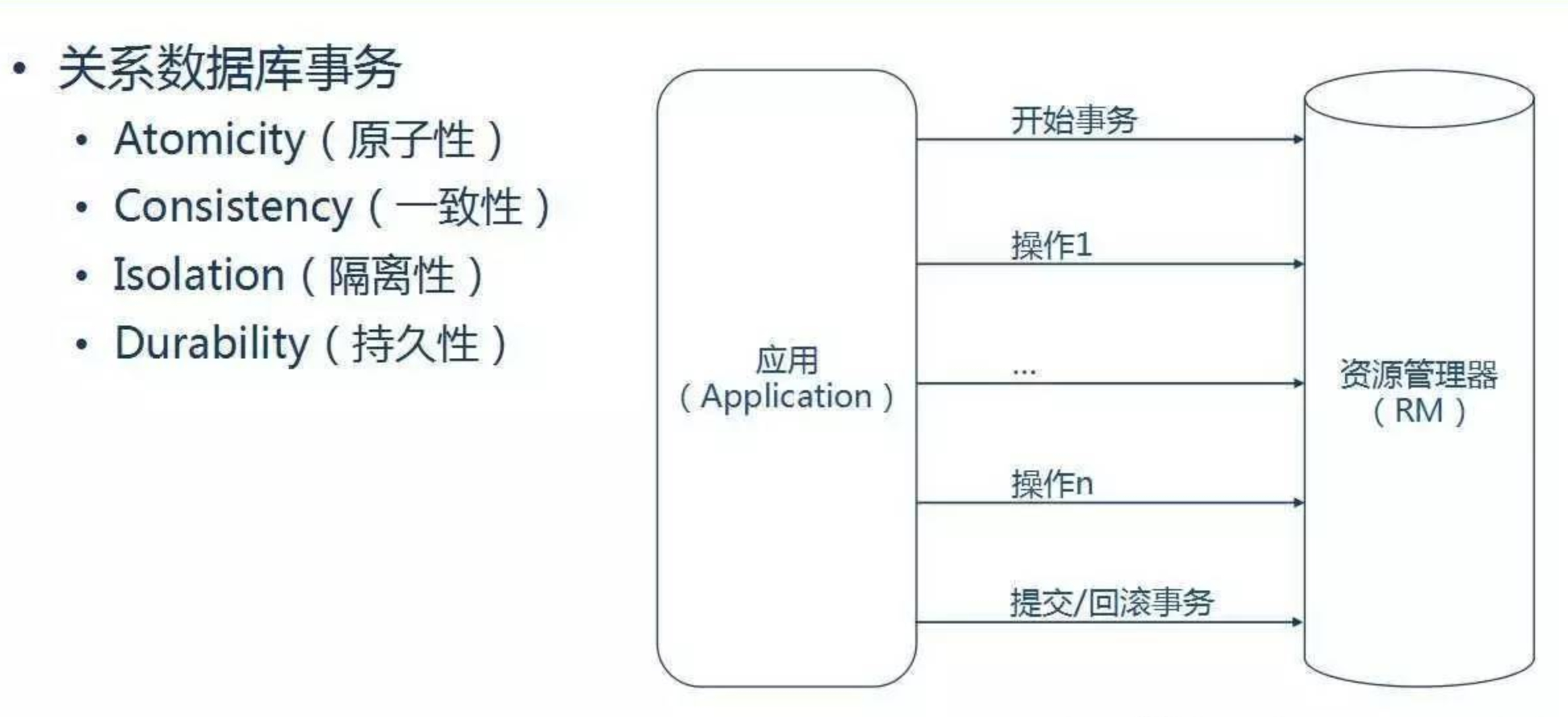
数据库事务操作也比较简单:开始一个事务,改变(插入,删除,更新)很多行,然后提交事务(如果有异常时回滚事务)。
1 | Connection con = null; |
更进一步,借助开发平台中的数据访问技术和框架(如:Spring),我们需要做的事情更少,只需要关注数据本身的改变。
随着组织规模不断扩大,业务量不断增长,单机应用和数据库已经不足以支持庞大的业务量和数据量,这个时候需要对应用和数据库进行拆分,就出现了一个应用需要同时访问两个或两个以上的数据库情况。开始我们用分布式事务来保证一致性。
二、分布式事务理论
2.1 CAP 定理
CAP 定理是由加州大学伯克利分校 Eric Brewer 教授提出来的,他指出 WEB 服务无法同时满足以下 3 个属性:
- 一致性(Consistency): 客户端知道一系列的操作都会同时发生(生效)
- 可用性(Availability):每个操作都必须以可预期的响应结束
- 分区容错性(Partition tolerance):即使出现单个组件无法可用, 操作依然可以完成
CAP 理论告诉我们,在分布式系统中,C、A、P 三个条件中我们最多只能选择两个。那么问题来了,究竟选择哪两个条件较为合适呢?
对于一个业务系统来说,可用性和分区容错性是必须要满足的两个条件,并且这两者是相辅相成的。业务系统之所以使用分布式系统,主要原因有两个:
- 提升整体性能:当业务量猛增,单个服务器已经无法满足我们的业务需求的时候,就需要使用分布式系统,使用多个节点提供相同的功能,从而整体上提升系统的性能,这就是使用分布式系统的第一个原因。
- 实现分区容错性:单一节点或多个节点处于相同的网络环境下,那么会存在一定的风险,万一该机房断电、该地区发生自然灾害,那么业务系统就全面瘫痪了。为了防止这一问题,采用分布式系统,将多个子系统分布在不同的地域、不同的机房中,从而保证系统高可用性。
这说明分区容错性是分布式系统的根本,如果分区容错性不能满足,那使用分布式系统将失去意义。
此外,可用性对业务系统也尤为重要。在大谈用户体验的今天,如果业务系统时常出现 “系统异常”、响应时间过长等情况,这使得用户对系统的好感度大打折扣,在互联网行业竞争激烈的今天,相同领域的竞争者不甚枚举,系统的间歇性不可用会立马导致用户流向竞争对手。因此,我们只能通过牺牲一致性来换取系统的可用性(A)和分区容错性(P)。这也就是下面要介绍的 BASE 理论。
2.2 BASE 理论
CAP 理论告诉我们一个悲惨但不得不接受的事实——我们只能在 C、A、P 中选择两个条件。而对于业务系统而言,我们往往选择牺牲一致性来换取系统的可用性和分区容错性。不过这里要指出的是,所谓的 “牺牲一致性” 并不是完全放弃数据一致性,而是牺牲强一致性换取弱一致性。下面来介绍下 BASE 理论。
- Basically Available(基本可用)整个系统在某些不可抗力的情况下,仍然能够保证 “可用性”,即一定时间内仍然能够返回一个明确的结果。
- Soft state(软状态)同一数据的不同副本的状态,可以不需要实时一致。
- Eventually Consistent(最终一致性)同一数据的不同副本的状态,可以不需要实时一致,但一定要保证经过一定时间后仍然是一致的。
BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual Consistency)。
有了以上理论之后,我们来看一下分布式事务的解决方案。
三、分布式事务
3.1 两阶段提交(2PC)
两阶段提交协议(Two-phase Commit,2PC)经常被用来实现分布式事务。一般分为协调器和若干事务执行者两种角色,这里的事务执行者就是具体的数据库,抽象点可以说是可以控制数据库的程序。 协调器可以和事务执行器在一台机器上。
在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的 ACID 特性,需要引入一个作为协调者的组件来统一掌控所有节点 (称作参与者)。
图示从支付宝向余额宝转账是怎样保证一致性的
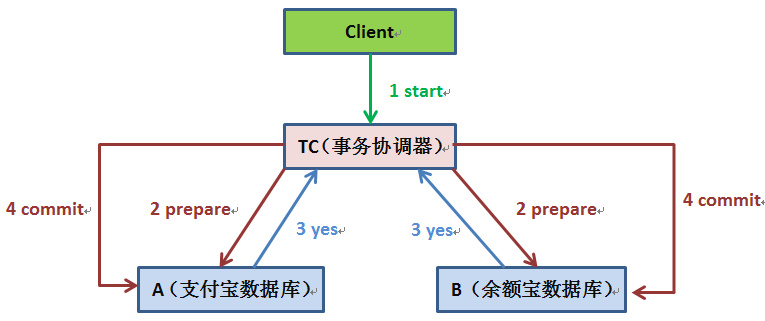
- 用户发起转账申请,首先到事务协调器
- 事务协调器通知(prepare)支付宝扣款,同时通知余额宝收款
- 支付宝、余额宝分别执行扣款、收款业务操作,本地事务不提交。并且把执行结果反馈给事务协调器,成功反馈 yes,失败反馈 no
- 事务协调器收到支付宝和余额宝的反馈如果都是 yes,则通知支付宝和余额宝系统提交事务(commit),否则通知回顾事务(abort)
- 事务协调器、支付宝和余额宝在整个过程收到通知都要记录日志(log),类似日常生活中的凭证。如果某个节点宕机,可以保证从日志中恢复后续操作。
两阶段提交这种解决方案属于牺牲了一部分可用性来换取的一致性。
优点: 尽量保证了数据的强一致,适合对数据强一致要求很高的关键领域。(其实也不能 100% 保证强一致)
缺点: 涉及多次节点间的网络通信时,牺牲了可用性,对性能影响较大,不适合高并发高性能场景,如果分布式系统跨接口调用。
3.2 补偿事务(TCC)
TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
- Try 阶段:主要是对业务系统做检测及资源预留
- Confirm 阶段:主要是对业务系统做确认提交,
Try阶段执行成功并开始执行Confirm阶段时,默认Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。 - Cancel 阶段:主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
举个例子,假如 Bob 要向 Smith 转账,思路大概是:
我们有一个本地方法,里面依次调用
- 首先在
Try阶段,要先调用远程接口把Smith和Bob的钱给冻结起来。 - 在
Confirm阶段,执行远程调用的转账的操作,转账成功进行解冻。 - 如果第 2 步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法(
Cancel)。
优点: 跟 2PC 比起来,实现以及流程相对简单了一些,但数据的一致性比 2PC 也要差一些
缺点: 缺点还是比较明显的,在 2、3 步中都有可能失败。TCC 属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用 TCC 不太好定义及处理。
3.3 分布式事务框架
常用开源的分布式事务框架:
- 阿里巴巴开源的分布式事务解决方案 Seata
- 一款事务协调性框架 TX-LCN
- 强一致分布式事务框架 Raincat
- 提供柔性事务的支持,包含 TCC, TAC(自动生成回滚 SQL) 方案 Hmily
- TCC 型事务 java 实现 tcc-transaction
- 基于事务管理器(TransactionManager)实现的 TCC 全局事务 ByteTCC
